As described here, statistical significance measures how much confidence you can have that a result from a study (e.g., a survey, observation, or experiment) represents the real world. That is, how likely are you to find the same results as those obtained in that survey, observation, or experiment if you were to go out and replicate the study yourself?
This applies to comparing conversion rates between BDRs, form-fill rates in an A/B test, sales cycle lengths for different solutions, or virtually anything else you might like to measure or compare.
Factors Influencing Statistical Significance
Whether a sample of any size can return a statistically significant result depends on a wide variety of factors, principally sample size, variability, and effect size.
Sample Size
The closer in size your sample is to the population or full set of things you are studying, the more likely you are to be able to find statistical significance.
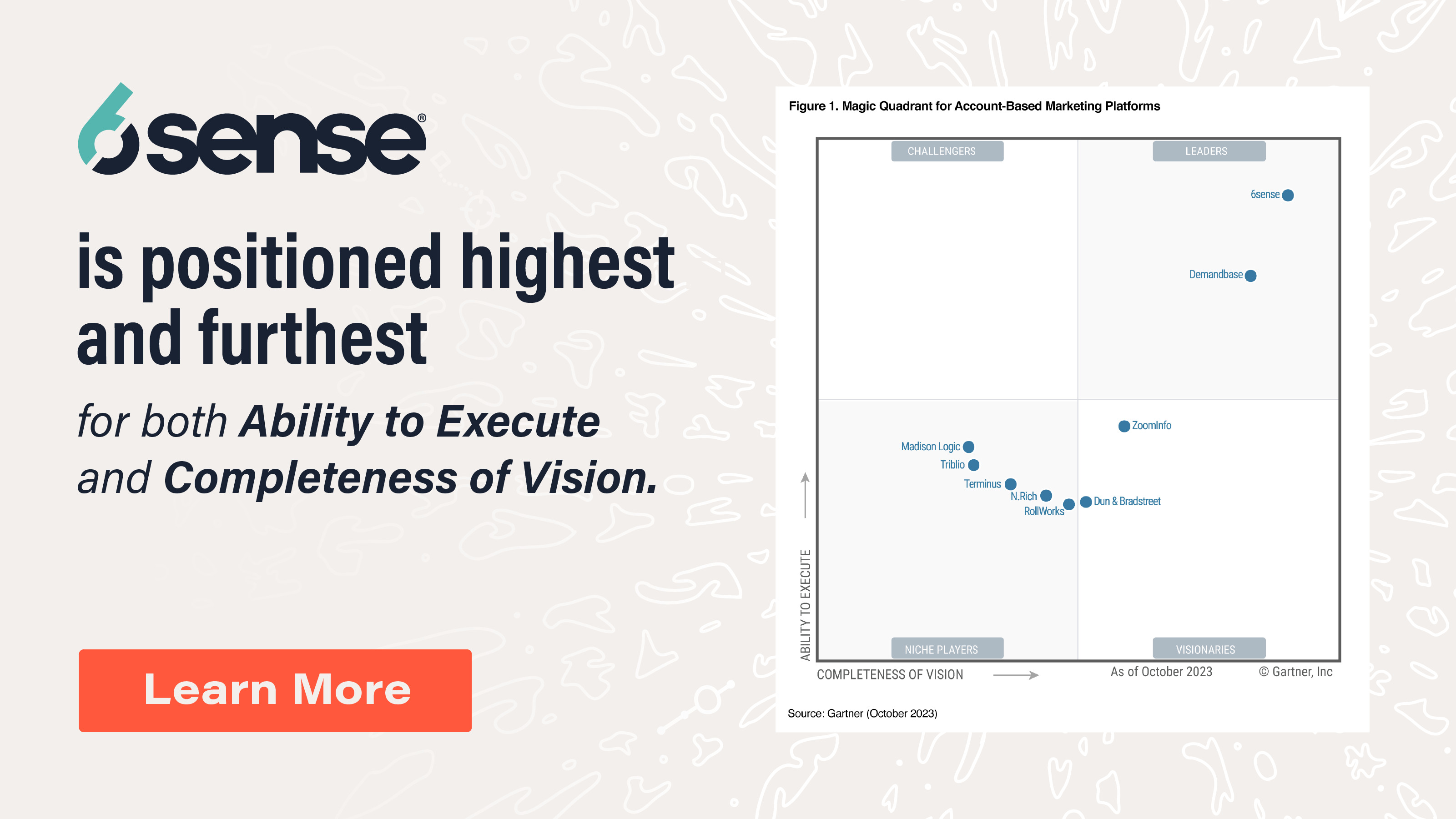
Example of the impact of sample size on statistical significance
Because statistical significance measures the probability that your sample represents the entire population – or the future outcomes – of what you are interested in, the closer you get to measuring them all, the more likely it is that your result will be statistically significant. For example, if you’re comparing the impact of using a sales engagement platform (SEP) on your company’s BDR opportunity production, you could test the productivity of two groups, one with the SEP and the other without. Both groups average exactly 10 opportunities per month prior to the experiment.
In a company with 1,000 BDRs, you could sample 100, with 50 BDRs in each condition (with and without the SEP) for one quarter. Having conducted this experiment, the difference in productivity between the two groups would be compared. A T-test would be conducted to assess whether the difference in productivity you observed was statistically significant.
A finding of p < .05 would indicate that there’s a 95% probability that the result you found in your sample would also apply to the entire population of BDRs. In this situation, a small observed difference in productivity (for example, 1 opportunity per month per rep) may not rise to the level of statistical significance. That is because it is likely that even if you chose your 100 BDRs at random, they still do not perfectly represent the total population of BDRs.
The math of the statistical test accounts for the difference between the size of your sample and the total population you are interested in.
- Sample size effect: If you ran the same experiment with 500 BDRs, finding a difference of 1 opportunity per month per rep may very well rise to the level of statistical significance. In this case, having sampled half of the population, the likelihood of finding that this relatively subtle difference is statistically significant (reliable) is naturally higher.
- Variability effect: If your BDRs produced an average of 10 opportunities per month prior to the experiment, but the BDRs themselves ranged between 10 and 20, an average improvement of 1 opportunity per month would likely require many months of data to rise to the level of statistical significance. If instead, the BDRs all produced 10 opportunities per month example, a finding that they now produced 11 would rise to the level of statistical significance in a much shorter window of time.
- Effect Size effect: If, on the other hand, BDRs produced 5 more opportunities per month after the new cadence was implemented, that much larger difference would be much more likely to rise to the level of statistical significance (reliability).
Variability
Another critical factor is variability. If there is a large range in the measures, scores, or responses of the thing you are measuring, then finding statistically significant patterns is harder. For example, let’s say that your company’s BDRs produce anywhere from 10 to 100 meetings per month, with the fluctuations obeying no clear pattern. Your company implements a new cadence for prospecting accounts and wants to know if the results it sees after the first month are due to the new cadence. In this high variability situation, it will be hard to know in just a month – or even several months – if any productivity difference is due to the new cadence or just happened by chance. However, if the team produces between 95 and 100 meetings per month regularly, with months rarely going below or above that small range, spotting differences due to new innovations will be much easier – both with and without statistics.
Effect size
If you are trying to find subtle changes or differences, it is likely that you will need a larger sample than if the differences you are looking for are larger ones. In the example of implementing a new BDR cadence on a team where productivity varies by plus or minus 5 opportunities per month, an effect size of five or fewer opportunities will be difficult to spot and require many months of data.
Control of the Environment
When researchers conduct controlled laboratory experiments where all or nearly all of the factors that might influence the experimental outcome are tightly controlled, very small samples are often sufficient to identify a statistically significant effect (or to rule one out). Put another way, if you are testing whether A affects B, and the only thing that can affect B is A, it doesn’t take many samples or experimental trials to see whether A does in fact affect B.
In our BDR example, there will always be many factors influencing BDR productivity in a given month, and many factors beyond your control will influence the number of opportunities produced. Finding a statistically meaningful difference in such an environment will require a substantial sample.







